
03. FlowSE:通过流匹配实现高效高质量语音增强
FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching
Interspeech 2025

摘要
Generative models have excelled in audio tasks using approaches such as language models, diffusion, and flow matching. However, existing generative approaches for speech enhancement (SE) face notable challenges: language model-based methods suffer from quantization loss, leading to compromised speaker similarity and intelligibility, while diffusion models require complex training and high inference latency. To address these challenges, we propose FlowSE, a flow-matching-based model for SE. Flow matching learns a continuous transformation between noisy and clean speech distributions in a single pass, significantly reducing inference latency while maintaining high-quality reconstruction. Specifically, FlowSE trains on noisy mel spectrograms and optional character sequences, optimizing a condition flow matching loss with ground-truth mel spectrograms as supervision. It implicitly learns speech’s temporal-spectral structure and text-speech alignment. During inference, FlowSE can operate with or without textual information, achieving impressive results in both scenarios, with further improvements when transcripts are available. Extensive experiments demonstrate that FlowSE significantly outper forms state-of-the-art generative methods, establishing a new paradigm for generative-based SE and demonstrating the potential of flow matching to advance the field. Our code, pre-trained checkpoints, and audio samples are available at https://github.com/Honee-W/FlowSE/.
Index Terms: flow matching, generative models, speech enhancement
生成模型在音频任务中表现出色,采用了语言模型、扩散模型和流匹配等方法。然而,现有的语音增强(SE)生成方法仍面临显著挑战:基于语言模型的方法存在量化损失,导致说话人相似性和可懂度受损,而扩散模型则需要复杂的训练且推理延迟高。为了解决这些问题,我们提出了FlowSE,一种基于流匹配的语音增强模型。流匹配通过单次处理学习噪声语音与干净语音分布之间的连续变换,可显著降低推理延迟,同时保持高质量重建。具体而言,FlowSE在噪声梅尔频谱图和可选的字符序列上进行训练,使用真实梅尔频谱图作为监督,优化条件流匹配损失。它隐式地学习语音的时-频结构和文本-语音对齐。在推理过程中,FlowSE可以有文本信息或无文本信息两种模式运行,在两种情况下都能取得出色效果,并且在有文字转录时效果会进一步提升。大量实验表明,FlowSE显著优于现有的生成方法,建立了生成式语音增强的新范式,并展示了流匹配推进该领域发展的潜力。我们的代码、预训练检查点和音频样例可在 https://github.com/Honee-W/FlowSE/ 获取。
问题
Q1:生成式模型和传统回归式模型
在语音增强(SE)里,“传统回归式模型”和“生成式模型”主要差在:它们怎么定义输出、怎么训练、推理时怎么产生结果。
传统回归式模型(regression / discriminative)
把 SE 当成一个“确定性的映射问题”:
- 形式:给定带噪输入 ,直接预测一个输出 。
输出通常是:- 干净语音波形 / 干净频谱(mel、STFT 幅度等)
- 或者一个 mask(如 ratio mask),再用 得到增强结果
- 训练目标:让预测结果尽量接近真值 ,比如 L1/L2、STFT loss、SI-SDR loss 等(本质是“拟合”)。
- 推理特点:一次前向就出结果(快、稳定)。
- 优缺点直觉:
- 优点:简单、高效、延迟低。
- 局限:它学的是“平均意义下最像”的点估计,遇到噪声很强或信息缺失时,可能会产生过度平滑、细节不够自然,或者在不同可能的干净解之间难以“选一个更合理的”。
一句话:回归式模型 = 直接预测一个最可能/最接近的答案。
训练损失:L1/L2、STFT loss、SI-SDR loss。它们都是“让输出更接近干净语音”的误差度量,但关注点不同。
L1 / L2 loss(点对点误差)
- L1(MAE):
更“抗异常值”,倾向保留尖峰/细节,听感上有时比 L2 不那么糊。- L2(MSE):
惩罚大误差更狠,容易得到“平均化”的解,可能更平滑。用在 SE 里:可以在波形上算,也可以在谱/梅尔谱上算。
STFT loss(频域一致性损失)
核心:不只比波形点对点,而是比较 短时傅里叶变换(STFT) 后的差异,尤其能约束 频谱形状 。
常见写法是组合:
- 谱幅度(magnitude)差:
- log 幅度差:
很多工作还用 multi-resolution STFT loss:用多个窗长/hop 同时算,兼顾细节与整体。
直觉:更贴近人耳对“频率结构/谐波”的敏感性,比纯 L1/L2 更不容易“音色跑偏”。
SI-SDR loss(尺度不变的信号失真比)
SI-SDR 是评价/训练里很常见的语音分离/增强指标,衡量: 在允许整体增益缩放的情况下,和 有多一致。
做法直觉:
- 先把 投影到 的方向(找一个最佳缩放系数 )
- 把投影部分当“目标”,剩下当“失真/噪声”
- 比它们的能量比(dB)
训练时通常用 当 loss(越大越好,所以取负号最小化)。
直觉:更关注“整体波形结构/可懂度相关的失真”,而不纠结于纯粹的幅度标定。
生成式模型(generative)
把 SE 当成“从条件分布里采样”的问题:
形式:学习条件分布 ,即“给定带噪语音 ,干净语音 可能有哪些样子”。
推理时不是直接算 ,而是从模型里生成/采样一个 。训练目标:不只是做点对点拟合,而是让模型学会这个分布。不同生成式方法的训练目标不同:
- 扩散模型(Diffusion):反复“擦干净”
把干净语音想成一张清晰照片。扩散的生成过程像这样:
- 训练时:故意把干净语音一步步加噪,模型学习“在第 t 步怎么把噪声去掉一点点”。
- 推理时:从“很乱的噪声”开始,一步一步去噪,比如 50、100 步……每一步都小幅变干净,最后得到增强语音。
直觉:像拿橡皮擦一点点擦干净。效果常很好,但步数多就慢。
- Flow Matching / Normalizing Flow:学一条“连续的清洗路线”
这类方法不是学“一步一步擦”,而是学一条“从噪声走到干净”的连续路线:
- 你可以想象有一条河流/传送带:把“噪声样子”平滑地“搬运”到“干净样子”。
- 模型学的是:在任意时刻应该朝哪个方向走、走多快(就像速度/方向的导航)。
- 推理时:用一个 ODE 求解器(常微分方程 ODE, Ordinary Differential Equation),沿着这条路线走一小段一小段(通常 10–20 步左右),就到干净结果。
直觉:像跟着导航走一条平滑的路线到目的地。通常比扩散需要的步数少,所以更快。
- LM + 离散 token:先“变成文字码”,再生成码,最后还原
这条路线会先把语音变成离散符号(token),类似把音频“压缩成一串编号”:
- 第一步:量化/编码
把语音切成一块块,每块用一个编号表示(token)。 - 第二步:用语言模型生成 token 序列
像做文本生成那样,预测下一个 token 是什么,从而生成“干净 token 序列”。 - 第三步:解码还原成语音
把 token 序列再还原成波形/频谱。
直觉:先把音乐变成“简谱编号”,再生成更好的编号,再演奏出来。
缺点是:这一步“变成编号”会丢掉一些细节(量化损失),可能影响音质/说话人相似度,很容易“像换了个人/口齿糊”。推理特点:通常需要“采样过程”(多步迭代或 ODE 求解),所以历史上常比回归慢。
优缺点:
- 优点:更擅长生成自然细节、处理“不确定/缺失信息”,在主观听感上可能更好。
- 局限:采样带来额外复杂度;有些路线(如离散 token)还会引入量化损失。
一句话:生成式模型 = 学“可能性空间”,推理时通过采样生成一个合理的答案。
1. Introduction
传统确定性方法缺点
在具有挑战的场景下自然度 不够,而生成式 更有潜力做高保真语音增强。
把“自然度”具体化:
- 不能只把噪声压下去,还得避免“金属音/机器人音/失真”;
- 这往往和模型有没有学到“干净语音的分布结构”有关。
两条主要生成式路线的缺陷
语言模型 LM 路线:量化过程信息丢失 → artifact(伪影) → 影响说话人相似度和可懂度。 FlowSE Efficient and HighQualit…
扩散 diffusion 路线:迭代随机去噪 → 计算重、延迟高。
flow matching 优点
高效的“一次式(one-shot)”生成范式:它学习一个连续的“速度场(velocity field)”,把简单的噪声分布转换到复杂的数据分布。
“simple noise distribution” 通常就是高斯噪声(很好采样、数学简单)。
“complex data distribution” 就是真实语音(或语音的 mel 频谱)在空间里的分布:结构复杂、带强先验(谐波、共振峰、语音节律等)。
“velocity field(速度场)” 是一个函数 :告诉你“当前状态 在时间 应该往哪里走、走多快”。
“one-shot” 在这里更像“训练目标是直接学这个连续速度场”,不是像扩散那样围绕随机去噪链条设计很多步的噪声日程/采样;但注意:推理仍然可能要走多步(用 ODE solver 积分),只是通常步数少很多。
high fidelity(音质/细节) + fast sampling(推理快)
FlowSE 架构
rectified flow matching + DiT backbone 组合
- flow matching:核心是学一个速度场 ,用 ODE 把起点分布推到终点分布。
- DiT backbone:DiT 就是用 Transformer(注意力)当主干来预测这个速度场。
要抓住的点:Flow matching 决定了“训练/采样范式”,DiT 决定了“用什么神经网络来实现 ”
训练输入: noisy mel + 可选 transcript
优化: condition flow matching loss
FlowSE 优点
不像以前用 U-Net 或 VAE,Transformer 更能抓长距离依赖,从而有助于保留说话人身份。
语音的结构经常是长程的:
- 时间上:一句话里前后几百毫秒甚至几秒的能量/韵律/发音位置有联系
- 频率上:谐波结构会跨多个频带相关
作者的观点是:Transformer 的自注意力更擅长把这些远距离关系“连起来”,从而更好重建复杂语音模式。
flow matching 学习的是一个连续变换/速度场(一个模型搞定),不走 LM 的离散 token(避免量化损失),也不走 diffusion 的长链迭代(避免很多步的去噪采样)
作者总结说:FlowSE 是一个 rectified flow matching + DiT backbone 的框架,目标是高保真且推理更快,并且强调能保留说话人身份;实验上改善质量、可懂度、说话人相似度,同时降低延迟。
思考三个问题:
快:到底快多少?用什么指标量化?
好:好在哪里?是主观质量、还是可懂度、还是说话人保持?
为什么:这些优势是来自 flow matching 还是来自 DiT 还是来自 mel+vocoder 的工程分解?
2. Related Work
2.1 生成式语音增强
传统 vs 生成式:
- 传统(CNN/RNN 等)主要做“确定性重建”,即输入 noisy,网络直接输出一个 clean(点估计)。
- 生成式模型学习 clean speech 的“分布”,因此对未知噪声的泛化更强。
早期生成式缺点:VAE / GAN
- VAE:有潜在建模优势,但常“过平滑”,不够锐利/高保真。
- GAN:感知质量可能更好,但训练不稳定、可能训崩/不稳定。
近年两大生成式主流:LM token 路线、diffusion 路线
LM + 离散 token:编码成 token 再用 LM 预测,但量化会丢信息,产生 artifact,伤害说话人相似度和可懂度。FlowSE Efficient and HighQualit…
Diffusion:随机去噪迭代,极端噪声下强,但计算重、推理慢,不利实时。
2.2 生成式建模的流匹配
作者先给出 flow matching 的定义:学习连续时间的概率流,把简单噪声分布变成复杂目标分布;并强调它直接学“确定性的、随时间变化的速度场”。
然后列举它在语音生成/增强/分离的成功应用:TTS(MATCHA-TTS、E2-TTS、F5-TTS)、增强(GF-VAE、FlowAVSE)、分离(FlowSep)。
最后一句很关键:这些工作要么依赖 U-Net/VAE,要么依赖视觉输入或 latent 映射;“纯音频 + Transformer + 可选文本条件”的框架还没被探索。这就是 FlowSE 的创新定位。
3. Proposed Approach
3.1 整体框架
语音增强:从带噪语音 里恢复干净语音 。
作者提醒:要做好这件事,不仅要建模声学信号,还要利用“可用的辅助信息”(比如文本转写)。
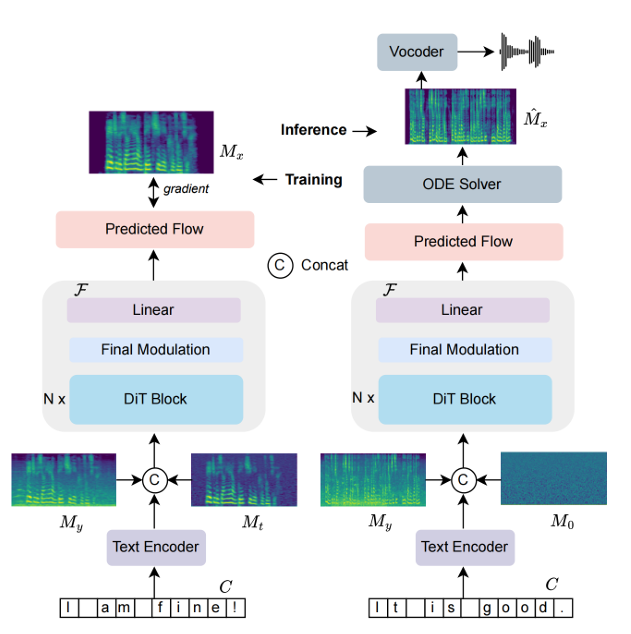
FlowSE 有三个关键组件:
组件 A:文本编码器 (可选)
组件 B:Flow-matching 生成模块 (核心)
组件 C:声码器
Figure 1 的数据流:训练和推理分别喂什么、产出什么
训练阶段(Figure 1 左边)
模型会同时看到三类输入:
- 带噪声的梅尔谱 noisy mel:
- 插值梅尔谱 interpolated mel:(由 干净语音的 mel + 高斯噪声 混合得到)
- 可选文本:转写
流程是:
- 文本 先过组件 得到文本 embedding;
- 文本 embedding 会和音频 embedding 拼接(concatenate);
- DiT-based flow model 预测概率 flow,并通过梯度更新训练,让它能重建干净 mel 。
可以先把 理解成“训练时的人造中间状态”:模型学习“从中间状态往干净方向推”。(为什么要这样做,3.2 会用公式讲清楚)
推理阶段(Figure 1 右边)
推理输入是:
- noisy mel:
- 初始高斯噪声:
- 可选文本:
然后:
- 模型预测的 flow 会“指导 ODE solver”生成增强后的 mel ;
- 最后用 vocoder 把 变回波形。
关键点(别搞混):noisy mel 是条件输入,而 是生成过程的随机起点。
关于推理的界定
“推理 / inference”在不同语境里有两种常见含义:
含义 A:通用机器学习语境(最广义)
推理 = forward 计算输出
也就是:给模型输入,跑一遍前向计算得到输出(不管你接下来要不要反传)。
所以在这个意义下:
- 训练里也有 forward(当然也算一种“推理动作”)
- 验证/测试/部署也有 forward
但为了避免混乱,大家通常不会把“训练里的 forward”叫 inference,而是叫 forward pass。
含义 B:论文/生成模型语境(更常见、也是这篇论文的用法)
inference = 部署/评估时的“生成/采样过程”(参数固定,不更新)
对 FlowSE 来说,这个“生成过程”不是一次 forward 就完事,而是:
- 从高斯初始化 出发
- 多次调用速度网络
- 用 ODE solver 反复更新状态
- 最终得到增强 mel
3.2 用于语音增强的流匹配
目的: 把“带噪分布”连续变成“干净分布”。
作者先把 SE 写成一个“分布变换”问题:把源分布 (比如 noisy speech)映射到目标分布 (比如 clean speech)。
不是直接学一个固定的 ,而是学一条“从 noisy 走向 clean 的路径”。
“学分布”不是背地图,是学“怎么把点搬过去”
关键是:我们要的不只是知道终点长啥样,而是要一个办法:
给我一个高斯里随机抽到的点 z,
我能按某种规则,把它“推着走”,最后它会落到双峰那两团里。这条“走的过程”就是论文说的路径: 随着 连续变化。
公式 (1):ODE = 这条“路径”的数学表达
论文给出核心 ODE:
横坐标是时间 ,纵坐标是状态 ,对 t 求导就是看这一时刻的瞬时斜率/瞬时变化率,就是我们说的速度场。
含义逐个拆开:
边界: 是起点(noisy), 是终点(clean)。
:中间状态。比如 时,你从 noisy 逐渐变到 clean 的中间状态。
:速度场(方向+速度)。模型学的就是它:在“当前状态、当前时间”下,下一瞬间该往哪走。
就像一张“正在被修复的语音”, 是修复指令。
是 3.2 用来讲“通用 flow matching”的抽象符号; 是 FlowSE 在 mel 域里的具体实例。它们说的是同一个“中间状态”,只是记号不同。作者先不限定你是在波形域、STFT 域还是 mel 域做,只想表达一个通用事实。这里 就表示“从源分布到目标分布过程中任意时刻的状态”。
公式 (2):推理时怎么“走”这条 ODE
真实 ODE 不能一口气算到终点,所以要离散成很多小步 。论文写了最基础的欧拉更新:
这时的 是在时间点 的斜率,但我们拿它当作在这段 内“差不多不变”,所以能算出一段时间后的变化量。
类比一下:
- 瞬时速度:此刻 60 km/h(时间点)
- 近似位移:假设接下来 1 秒都差不多 60 km/h,那位移 ≈ 60 km/h × 1 秒(时间段近似)
这就是“每一步”在干嘛:用模型给的速度,往前走一小段。
如何理解?
ODE 描述的是“单个样本怎么动”(微观规则);
分布 描述的是“很多样本整体长什么样”(宏观云团)。
当你让“很多点”都按同一个 ODE 规则走,这团点云(分布)就会被一起搬运,从而实现 。
3.3 Network Architecture
FlowSE 采用三阶段处理:mel-spectrogram encoder 、基于 latent DiT 的 Flow Matching 模型 、以及用于波形重建的 vocoder 。
3.3.1 Mel-Spectrogram Encoder: 做什么?
这里作者强调:FlowSE 不是学一个神经网络编码器,而是“直接用传统信号处理”提 mel。
输入输出与公式 (3)
- 输入:原始波形
- 输出:noisy mel (=mel 频带数,=帧数,指的是这个输入是个矩阵,行是频带数,列是帧数,元素是 log 功率/能量)
- 计算:STFT + mel-filterbank:
要点
这一步把语音从“波形(很长的一维序列)”变成“时频图(二维)”,后面的生成/增强都在这个二维空间进行。论文也明确说:这个表示将作为 Flow Matching 模块的输入。
**STFT(短时傅里叶变换)**把长长的波形 切成一帧一帧的小窗口,对每一帧做频谱分析,得到“时间 × 频率”的表示。
目的:
- 把时间域的一维信号变成时频图:语音的谐波、共振峰、噪声能量更容易在频域区分。
- 把问题变成“在时频图上修复/去噪”:很多增强模型更擅长处理这种二维结构。
mel-filterbank 是一组滤波器,把 STFT 的线性频率轴“压缩/重采样”到 mel 频率轴(更贴近人耳分辨率:低频更细、高频更粗)。
目的:
降维:从 FFT 的很多频点变成较少的 mel bin(论文训练用的是 100 维 log mel-filterbank)。
“压缩/重采样”具体在做什么?
mel-filterbank 可以理解成一堆三角形滤波器,每个滤波器覆盖一段 STFT 频率 bin,把那一段的能量加权求和,得到一个 mel bin。
- 输入:很多个线性频率 bin(比如 513 个)
- 输出:较少的 mel bin(论文里用 100 维 log mel)FlowSE Efficient and HighQualit…
所以这一步既是:
- 换坐标(线性 Hz → mel 标度)
也是- 降维(频率 bin 数变少)
更符合听觉相关的表示:很多 TTS/vocoder 都以 mel 为主要条件输入,因此生态成熟。
线性频率轴 vs mel 频率轴:哪里不一样?
- 线性频率轴(STFT 原始频率 bin)
STFT 的频率 bin 是等间隔的:
- 例如采样率 24 kHz,FFT 点数为 ,频率间隔大约是 Hz
- 第 1 个 bin、第二个 bin、第三个 bin……每个 bin 之间相差都是同样的 Hz
比喻:像尺子一样,每一格都是 1 mm。
- mel 频率轴(mel filterbank 后)
mel 轴不是等间隔 Hz,它是按“人耳分辨率”设计的:
- 低频(比如 0–1000 Hz)人耳更敏感,需要更细的分辨,所以 mel 会分得更密
- 高频人耳分辨率变粗,所以 mel 会分得更稀
比喻:低频像用更细的尺子,高频像用更粗的尺子。
3.3.2 Flow Matching + Latent DiT:核心模块速度场网络 做什么?
Flow Matching 和 DiT 一个是“训练/生成的数学框架”,一个是“用来实现那个框架里关键函数的神经网络”。
Flow matching 规定了三件事:
- 要学的东西是什么:一个速度场(velocity field)
也就是学 这个函数。
- 推理/生成时怎么用:用 ODE 求解(多步更新)
- 训练时怎么学:用 flow-matching loss 去逼近“正确的速度”(论文后面把它叫 probability flow / velocity field)。
所以可以把 flow matching 理解为:一套“怎么把噪声状态一路推到干净状态”的动力系统设定 + 训练方法。
DiT 直接在 mel 域上工作,学习一个随时间变化的速度场 ,用来引导“从噪声/中间态到干净”的变换过程。
DiT 在这里不是“做扩散”,而是作为 速度场估计器,学习:
也就是:给定当前中间态 和进度 ,再加可选文本条件 ,输出速度场。
然后用 ODE solver 更新:
训练阶段:模型吃什么?
训练时有三类输入(这是你实现时最关键的清单):
- noisy mel:
- 中间态 mel: —— 由 clean 目标 与 高斯噪声线性组合得到
- 可选文本条件:(来自转写)
并且作者点明训练目标:速度模型要估计“probability flow”,让 随着时间推进被运输到 。
“probability flow(概率流)描述的是:一整团样本(概率分布)在空间里如何随时间“流动/搬运”。
而模型学的 速度场 就是在告诉你这股“流”每个位置、每个时间该往哪走。把它拆开讲:
- 为什么叫“概率流”?
想象你有很多点(很多条语音样本的表示)组成一团“云”。
- 这团云在 时长得像“噪声/带噪”的分布
- 你希望它在 时变成“干净语音”的分布
如果我们规定每个点都按同一个规则运动:
那么整团云也会一起被带着动。
这团云的“整体运动方式”就叫 probability flow。
- 它和“速度场”是什么关系?
- 速度场 :微观层面,告诉“某个具体点此刻往哪走”。
- 概率流:宏观层面,描述“整团概率质量怎么被搬运”。
所以论文说“速度模型要估计 probability flow”,就是在说:模型要学出一个速度场,让它驱动分布从源搬到目标(从 noisy/噪声搬到 clean)。这也是 Flow Matching 那句“transport simple noise distributions to complex data distributions”的同一件事。
关键理解:
- 是“条件证据”(告诉模型这次要增强哪段语音)
- 是“路径上的当前状态”(让模型学会任意进度 时该怎么动)
- 只在训练时出现:既用来构造 ,也提供监督信号
具体流程:
准备监督对
从分布为 的数据集中 随机抽取 一对带噪声和干净的语音对 。
每一对样本都有一些“属性”:
- 说话人:男/女
- 噪声类型:街道/咖啡厅/风扇
- SNR:0dB / 5dB / 10dB(越小越吵)
- 语速、口音、句子长度…
以噪声类型统计为例(这就是“分布”的一种)
比如 10 条里:
- 街道噪声:6 条
- 咖啡厅噪声:3 条
- 风扇噪声:1 条
那你就可以说:在这个数据集里,噪声类型的经验分布大致是:
这就叫“分布”。它回答的是:你更常遇到什么样的噪声样本。
构造中间态
由 clean 目标 与 高斯噪声“线性组合”得到。
它没有把组合公式写出来。但在 rectified/flow-matching 的标准做法里,最常见的一种就是:
采样
采样
做线性插值:
- 当 :(几乎纯噪声)
- 当 :(完全干净)
所以方向是:从噪声 → 干净(t 变大,干净占比变大)。但要注意的是:训练时通常是随机采样很多不同的 ,让模型学会在任意进度点的“速度”,不是按顺序从 0 走到 1 生成一条曲线。
具体的操作是:
随机抽一个时间点
这是“生成进度条”的随机位置(不是音频真实时间)。
随机采一个高斯噪声张量
这里的“采样”不是“在高斯曲线上挑一点”,而是:
为每个元素(每个 mel bin × 每个时间帧)独立生成一个高斯随机数,得到一个和 同形状的噪声矩阵。
现在把 (clean mel)想成一个很大的表格 (F×T):
- 行:mel 频带数(比如 100 行)
- 列:时间帧数(比如 300 列)
也就是 的形状可能是 (100, 300)。
“生成同形状的高斯噪声 ”就是:
生成另一个 (100, 300) 的表格 ,并且 每个格子里都随机填一个“服从高斯分布”的数(均值 0、方差 1)。举个小一点的例子,如果 是 (2,3),那我们生成:
这里的 0.2、-1.1、1.7…每一个都是独立随机从 抽出来的。
构造中间态,计算时对每个格子都这样算:
每个位置 都按同样的公式混合。
这一步的意义:让模型在各种进度 都见过“路径上的点”,从而学会整条路径的速度场。
处理文本条件(可选,并且训练时会 dropout)
当你有转写 时:送入文本编码器 ,并在训练中随机丢弃文本输入以增强泛化,让模型同时适配“有文本/无文本”。
Figure 1 还说文本 embedding 会与音频 embedding concat 后喂给 DiT。
DiT 前向,输出速度场
把 送进 DiT(实现上就是 ),得到:
- 输出:(速度场)
关键点:训练时网络的“主要输出”就是速度(flow/velocity)。
输入 是一个 的 mel 矩阵。
输出 也必须是 同形状(或可 reshape 回同形状)的矩阵:
它表示:对每个时间帧、每个频带位置 ,模型都给出一个“瞬时变化率/更新方向”。
怎么定义 loss
论文在 3.4 说:FlowSE 用 flow-matching loss 学最优速度场,指的是预测的速度和真实值之间还要计算一个 loss 用来训练这个速度场,让让模型输出的速度 尽量等于“正确速度”。
构造中间态时:
因为这条路径是线性插值,所以速度能从中间态直接算出来真值:
flow-matching loss 一般/最常用的就是:
其中 :网络输出的“速度”。
就是“逐元素平方再求和/求平均”,所以是一个标准的均方误差(MSE)。
损失里写的期望 ,在训练实现里几乎总会变成“样本平均”(mini-batch average)
在重构语音阶段,再加入 mel 的 L1 重建损失:
其中 是预测的 clean mel。
速度场 + ODE 更新规则 ⇒ 定义了一条从起点到终点的生成过程;走到终点的那个状态就是 。
3.3.3 Vocoder: 怎么把 mel 变回波形?
最后阶段用预训练神经声码器(Vocos / BigVGAN)把增强 mel 还原成波形。
公式 (6):
其中这里的 指“Flow Matching 模型预测出来的增强 mel”。
作者强调“解耦”的好处:增强在 mel 域进行(训练/推理更高效),同时利用强大的预训练 vocoder 来保证波形质量。
3.4 训练目标
论文明确给了一个 L1 重建损失:
并解释 是模型预测的 clean mel。
背景补充:L1 是什么?
L1 就是“绝对值差的平均/求和”。对每个元素:再把所有元素加起来(或平均)。它鼓励“整体误差小”,通常比 L2 更不容易被极端值主导。
论文只说 是 predicted clean mel,没有写它怎么计算。
通常实现里有两种做法(都和论文不矛盾):
做法 A:训练时也跑一小段 ODE(和推理同款)
用式(4)跑 N 步,把初始 (高斯噪声)一路走到 ,得到 ,再算 L1:
优点:训练/推理完全一致;缺点:训练更慢。
做法 B:用“一步近似”从 直接得到
因为你在训练时随机拿到一个 ,你可以用“速度 × 剩余时间”做一步近似走到终点:
然后再用式(7)算 L1。
优点:训练快;缺点:近似误差大一些,所以通常要配合 flow-matching loss 一起训。
那“flow-matching loss”和 mel L1 是什么关系?
可以这样理解:
- flow-matching loss:直接监督/约束网络输出的“速度场是否合理”(论文说用它学习最优速度场)。
- mel L1(式7):约束“走到终点后,生成的 真的接近 GT 的 ”。
所以训练里通常是:
( 是权重)
一个管“每一步方向对不对”,一个管“最终到没到对的地方”。
3.5 问题
Q2:ODE 常微分方程
ODE 是 常微分方程(Ordinary Differential Equation)。
它描述的是:一个量会随着“时间”连续变化,而它变化的速度由某个规则决定。
例子
- 位置 随时间变
- 速度 决定位置怎么变
这就是:
左边 叫“导数”,也就是“变化速度”。
Q3. 为什么需要中间态 ?
Flow matching 要学的是一个随时间 变化的速度场 。如果你只在“起点”和“终点”训练,那模型不知道:
- 在“离目标很远”的时候该怎么走
- 在“已经接近目标”的时候该怎么微调
所以训练时要让模型看到“路径上的各种位置”,这就是 的作用:
它提供了大量“处在不同进度 t 的状态样本”,让模型学会在任意 t 时刻的局部更新规则(速度)。
这也是 flow matching 的基本思想:用连续动力系统把简单分布搬运到复杂数据分布。
- 每次训练迭代里,你确实只“拿到一个中间态” (对应一个随机 )。
- 但这个 不是固定的一个中间点,而是从 连续区间里随机抽的。
所以从全局看,训练并不是“三步”,而是:
用很多次迭代覆盖了整条路径上的无数个点
(有的点非常靠近起点 ,有的点非常靠近终点 ,有的点在中间)。
你可以把它想成:每次训练只抽查“进度条”上的一个位置,但抽查次数足够多后,进度条几乎每个位置都被抽查过了,于是网络学会了在任意进度该怎么走。
推理时你真的要从 走到 。既然速度依赖于“当前状态 + 当前 t”,那你必须:
- 走一步 → 状态变了、t 变了
- 再算一次速度 → 再走一步
- 重复多次(比如 10–20 步)
训练是“随机抽点学局部规则”,推理是“把这些局部规则串起来走完整条路”。
4. Experiments
4.1 数据集与评估指标
训练集怎么构造?
作者把多个公开的语音数据集和噪声数据集拼在一起做大规模训练:
- 语音(干净语音来源):WeNetSpeech、GigaSpeech、VoiceBank(VCTK)、DNS Challenge - Interspeech 2021 数据集
- 噪声(环境噪声/人工噪声来源):WHAM!、DEMAND、DNS Challenge - Interspeech 2021 数据集
- 房间脉冲响应 RIR(用于混响/房间效果):OpenSLR26 和 OpenSLR28
- 他们还做了筛选:过滤掉非英文和非中文语音
- 文本转写(transcription)用 OpenAI Whisper 得到(用于可选的文本条件)
目的:
- 拼多个语音库:让说话人、口音、录音条件更丰富,模型更不容易“只会某一种声音”。
- 噪声库 + RIR:噪声解决“吵”,RIR解决“混响”(房间反射导致拖尾、发闷)。
测试集怎么做?
作者用了两种测试:
- 官方 DNS Challenge - Interspeech 2021 test set:用来和 SOTA 方法公平对比
- 自己合成的模拟测试集:用 VCTK 的干净语音 + “没在训练里出现过的”WHAM!/DEMAND 噪声进行混合,并控制 SNR 从 -5dB 到 10dB
背景知识:SNR(信噪比)越低越难,比如 -5 dB 表示噪声能量比语音还强,属于“很极端”的情况。
用什么指标评估?
作者强调:像 PESQ、SI-SNR 这类传统指标对生成式模型可能不准,因为生成式输出常常和原始波形对不齐(alignment 不一致),指标会被“对齐误差”误导。
所以他们用三类更适合的指标:
- DNSMOS:用神经网络估计 MOS(主观听感评分),并且和人类评分相关性较好
- Speaker cosine similarity(说话人相似度):用 WeSpeaker 提取说话人 embedding,再算余弦相似度,衡量“增强后还是不是同一个人
- WER(词错误率):用 Whisper 转写增强语音,再算 WER,衡量可懂度/识别友好程度
4.2 训练设置
- 输入表示:模型输入不是波形,而是 log-mel 特征
作者把 24 kHz 的音频转成 100 维 log mel-filterbank(对数梅尔滤波器组),并且 hop length = 256(每 256 个采样点算一帧的步长)。
把这个 hop 换算成时间更直观:
- 采样率 24,000 Hz ⇒ 1 秒 24,000 个采样点
- hop = 256 个采样点
- 所以帧移 = 秒 ≈ 0.010666… 秒 ≈ 10.7 ms
这意味着:模型处理的序列是“每 10.7ms 一个时间帧”的 mel 特征序列(频率维度是 100)。
- 主干网络:DiT(Transformer)来预测速度场
他们用 latent Diffusion Transformer (DiT) 当作速度场估计器。配置是:
- 22 层 Transformer block
- 16 个 attention head
- hidden size 1024
- FFN(前馈层)维度 2048
这些超参在干嘛:
- 层数:越多越“深”,表达能力更强但更慢、更难训
- head 数:相当于“多路注意力视角”,帮助同时关注不同的时频模式
- hidden size / FFN size:每层内部的“通道宽度”,越大越能装信息,但算力/显存更贵
这篇 FlowSE 论文在 4.2 只给了配置(22 层 / 16 heads / hidden 1024 / FFN 2048),并没有写这些超参是通过什么 ablation(消融)或系统搜索得到的。
所以我们只能根据通用的工程逻辑 + Transformer/DiT 的常见做法来解释“通常怎么定、为什么这样定合理”。
这些超参通常怎么确定?
1) 先从“已有的成熟模板”出发(DiT 配置)
他们明确说用了 latent DiT 作为速度场估计器(velocity field estimator)。
学术/工程上很常见的做法是:先选一个在类似任务上验证过的 DiT 规模当起点,再围绕算力/速度做微调,而不是从零开始网格搜索。2) 16 个 head + hidden 1024:是一个“很整齐、很常用”的拆分
因为:
- hidden = 1024
- heads = 16
⇒ 每个 head 的维度64 是注意力里非常常见的 head 维度(实现高效、数值稳定、也符合很多公开模型习惯)。这类“整除且 head_dim 合理”的组合往往是首选。
3) FFN 2048:明显是“为效率做的取舍”
很多标准 Transformer 会用 FFN = 4×hidden(比如 4096),但他们用的是 2×hidden(2048)。
这通常意味着:作者在 表达能力 vs 计算量/延迟之间偏向后者(你也提到他们目标是实时/低延迟场景)。FFN 是 Transformer 里最吃算力的部分之一,减小 FFN 是最直接的加速手段之一。
4) 22 层:在“足够深”与“训练/推理成本”之间折中
层数越多,一般建模能力越强(尤其是时序长程依赖),但显存/计算也线性增长。作者选择 22 层并配合 dropout、梯度裁剪、warmup 等稳定训练手段(这些都写在 4.2 里),属于“规模不小但还可训、可跑”的典型折中。
一句话总结
- 论文没有公开“怎么搜索出 22/16/1024/2048”的过程,只给了最终配置。
- 从工程角度看,这套超参非常像:沿用成熟 DiT 规模 + 让 head_dim=64 的整齐拆分 + 把 FFN 设得偏小以换速度/RTF。
- 文本条件:用 ConvNeXt V2 做 text encoder(字符级)
如果有转写文本,他们用 ConvNeXt V2 做文本编码器:
- embedding 维度 512
- FFN 维度 1024
- 处理的是从转写里抽取的 character sequences(字符序列)
这对应前面的“可选文本条件 C”:有文本就把文本特征喂给模型;没文本也能跑。
- 波形怎么回来:用预训练 Vocos vocoder 合成
mel 预测完以后,作者用预训练的 Vocos 把 mel 还原成波形(增强语音)。
他们不显式预测相位,而是交给 vocoder 在合成时隐式解决。
- 怎么训练:AdamW + warmup + 线性衰减 + 稳定技巧
训练细节:
- 优化器:AdamW
- peak learning rate:7.5×10⁻⁵
- 学习率:前 20K step 线性 warmup,然后线性衰减
- dropout:attention 和 FFN 都用 0.1
- 梯度裁剪:gradient norm clip 到 1
- 训练规模:8 张 NVIDIA 4090D,跑 1.2 million updates
这些“稳定训练”的手段(dropout、grad clip、warmup)在 Transformer/生成模型里非常常见,尤其是这种比较大的 DiT。
4.5 问题
Q4:稳定训练的目的和原因
稳定训练”的目的可以概括成两句话:别崩(不发散/不出 NaN/不爆梯度),以及稳稳收敛到一个泛化更好的解(不在训练早期乱跳、后期不震荡)。
下面把论文里提到的几点分别说清楚“它在防什么问题、为什么这么设”。
论文用了哪些稳定训练设置
- AdamW
- peak lr = ,前 20K steps 线性 warmup,然后线性衰减。
- attention/FFN dropout = 0.1;gradient norm clip 到 1;8 张 4090D 跑 1.2M updates。
AdamW 是一种更稳、更“好泛化”的默认选择。
可以把训练流程分成三步:
前向(forward):输入 → 模型 → 输出(比如速度场、)
算损失(loss):输出和目标之间差多少
反向(backward):把损失对参数的梯度 算出来
损失对参数的梯度
- 是 损失函数:衡量模型做得有多差(越小越好)。
- 是 模型参数:比如网络里的权重、偏置(训练时会更新的那些数)。
- 读作:“ 对所有参数 的梯度”。
如果只看一个参数 ,那就更简单:
这表示:当我把 稍微增加一点点,损失 会怎么变化?
梯度就是变化率。
- 一维时: 是斜率
- 多维时: 是一个向量,里面每个分量都是对应参数的“斜率”
并且它有一个关键性质:
梯度指向“让 增加最快”的方向。
所以 就是“让 减小最快”的方向。最朴素的梯度下降(SGD)写成:
( 是学习率,控制步子大小,普通的梯度下降都用同一个学习率)
参数更新(step):用优化器把 更新一下
AdamW 就是出现在第四步中,它决定了每次反向传播算出梯度以后,模型参数 该怎么更新。
AdamW = Adam + “解耦的 weight decay”(更干净的权重衰减),Transformer 里几乎是默认选择。
weight decay 是什么?
是一种正则化方法,简单说就是“把参数往 0 拉一拉”,避免模型权重变得过大、过拟合。
训练时我们要最小化损失 。
加上 weight decay 后,相当于你优化的是:
其中 是所有参数的平方和, 是强度。一般为了求导时干净,也会写作 。
- 如果某些权重变得特别大,模型容易“死记硬背”训练集或训练不稳定
- weight decay 会惩罚“大权重”,让模型更平滑、泛化更好
最朴素的梯度下降(SGD)是:
所有参数都用同一个学习率 。
而 Adam 的核心思想是:
每个参数都自动调自己的步长(自适应学习率),并且带“动量”让更新更平滑。
它会为每个参数维护两种统计量:
- 一阶动量 :梯度的滑动平均(类似“速度/惯性”)
- 二阶动量 :梯度平方的滑动平均(反映梯度尺度)
然后用它们来缩放更新幅度:梯度大/不稳定的参数会被“缩小步子”,梯度小的参数步子相对更大一些。
损失上加了 weight decay ,那么把损失对参数求梯度时,就会将 weight decay 也算进去。
“Adam + L2 正则”(很多人也把它叫 Adam with L2 regularization):
那梯度就是:
然后 Adam 用这个“混在一起”的梯度去做自适应更新。
“Adam + L2”(耦合版)的更新(概念式)
注意:这里 会被 Adam 的自适应机制缩放(因为它进了同一个梯度管道)。
AdamW(解耦版)的更新(概念式)
AdamW 分两件事做:
(A) 先按纯任务梯度做 Adam 更新:
(B) 再做一次显式的权重衰减:
合起来也常看到写成一条:
关键区别是:这里的 不会被 Adam 的自适应缩放影响,它就是“干干净净地把权重往 0 拉”。
为什么这很重要?
Adam 是“梯度大的地方少减点、梯度小的地方多减点”。
如果把 weight decay 也塞进梯度里(),那么:
- 对某些参数,Adam 可能因为二阶统计量把更新缩小/放大
- 结果 weight decay 的强度也被缩小/放大(变得不可控)
- 本来想要“统一强度的正则”,结果每个参数的正则强度不一样了
AdamW 的“解耦”就是为了解决这个:
让 weight decay 的行为和 SGD + weight decay 一样可控,同时保留 Adam 的自适应优势。
7.5e-5 是 AdamW 的 peak learning rate(峰值学习率)。它只在训练的“参数更新”那一步起作用。
最简梯度下降的更新形式为:
这里 就是学习率(lr)。lr 越大,每一步改参数改得越猛;越小,每一步更保守。
在论文里,学习率随训练步数变化的计划(schedule) :前 20K steps 线性 warmup 到 7.5e-5,再线性衰减。
warmup
warmup = 热身:训练一开始不要用很大的学习率,而是从很小开始,随着训练步数逐渐增大,直到达到峰值学习率(这里是 7.5e-5)。
如果 warmup 20,000 steps,最常见写法是:
- 第 0 步:lr ≈ 0
- 第 10,000 步:lr ≈ 0.5 × 7.5e-5
- 第 20,000 步:lr = 7.5e-5(到达峰值)
公式(线性 warmup):
其中 是当前 step,,。
线性衰减
这里的“线性衰减”指:warmup 结束之后,学习率随着训练 step 继续增加而逐渐变小,一直降到接近 0(或一个很小的值)。
最常见写法:
也就是说它随着训练进行(step 变大)而衰减。
论文也给了总训练步数:1.2 million updates。
所以可以理解为:20k 之前升,20k 之后从峰值一路线性降,到 1.2M 左右接近 0。
warmup:刚开始“别猛踩油门”,学习率稍微大一点就可能:loss 爆炸、梯度爆炸、出现 NaN,避免训练早期不稳定。
衰减:训练中后期如果 lr 一直很大,loss 会在谷底附近来回抖,生成质量也会不稳定。后期“慢慢松油门”,让模型收敛得更细致、更稳定。更容易把细节(比如语音细纹理、说话人特征)“磨”出来。
Dropout = 训练时随机把一部分神经元输出“置零”,让模型别太依赖某些特定特征/通路。
最简单例子🌰:一个向量
dropout=0.1 表示每个元素有 10% 概率被丢掉。比如一次随机后可能变成:
为什么能防过拟合?
过拟合的一个典型原因是:模型学到了“捷径”——只靠少数几个特征就把训练集拟合得很好,但这些捷径在新数据上不成立。
Dropout 的作用是:
你每次训练都随机“掐断一些路”,迫使模型必须学更稳健、更多路都能用的表示。
可以把它想成:
- 没 dropout:模型可能靠“某一条强特征通道”就把训练误差压低(容易记住训练集)
- 有 dropout:那条通道可能被随机掐掉,模型不得不学“备用方案”(泛化更好)
但是引入 dropout 会出现数值尺度偏移,我们如何探究偏移了多少呢?这就要引入期望(平均)。
假设某一层本来(没有 dropout)输出一个数:
当开启 dropout 时(丢弃概率 )
训练时每次 forward 会随机一个 mask :
- 以 0.9 概率 (保留)
- 以 0.1 概率 (丢弃)
dropout 后输出是:
所以一次输出只能是:
- 10(保留)或 0(丢弃)
既然 dropout 是个随机事件,每次结果可能不同,我们就会问:如果 重复很多很多次,平均结果大概是多少?通过这个平均结果(期望)我们就能看出来出现了怎样的偏移。
原本应该直接输出 10 的,但是有了 dropout,输出的平均可能就变成了 9 。这就叫期望偏移:
原来重复多次的话“平均”是 10,现在因为随机丢弃,平均变成了 9(变小了 倍)。
这就引出了一个问题:训练时丢,推理时还丢吗?
不丢。
- 训练(train mode):随机置零(制造扰动)
- 推理/测试(eval mode):不置零,用完整网络
那么两处操作不一致,参考上文提到的期望偏移。
举个🌰:
训练时,有丢弃,数值尺度是 9 (上文的例子),到推理阶段,因为不丢弃了,因此数值尺度是 10,如果再一层层的传下去,最终可能发生很大的偏移。
如何保证“训练时丢了还能学,推理时不丢也不改变数值尺度”?更准确叫:激活分布/数值尺度(activation scale)不要发生 train/eval mismatch。即,如何在丢弃的时候还能把这个尺度纠正过来,从而保证训练和推理的尺度相似,逻辑上也就是期望相似。
实现里通常用 inverted dropout 。
逻辑就是:丢弃的地方只能归零,那么保留的地方进行放大,最终的平均期望就是相似的了。
把 dropout 后输出改成(参考上一节的公式 ):
也就是说:
- 保留时():输出
- 丢弃时():输出 0
在 时,,所以保留时输出:
再算期望:
平均值回到了 10 —— 这就是缩放的目的:把期望偏移“补回来”。
同时,因为丢弃,模型每次训练都会遇到一点点随机扰动(有些特征被掐掉),模型会被迫学习更加稳健的表示,不会因为特征/线索缺失就处理不了,从而对噪声更加不敏感,起到了正则化的效果。
缩放是为了“别整体偏掉”;波动是为了“别太死记
(等待补充)
(等待补充)
(等待补充)
Q5:什么是正则化?
“正则化(regularization)”这个词听起来玄,其实意思很朴素:
在“把训练误差变小”之外,再加一条规则,让模型别学得太离谱,从而更能在新数据上表现好(泛化更好)。
L1 和 L2 等只是常见的两种正则化形式。
为什么需要正则化?
模型太强时会出现“背答案”:
- 训练集上 loss 很低
- 换到没见过的数据就变差(过拟合)
正则化就像给模型加“约束/惩罚”:
- 让它偏向更简单、更平滑、更不极端的解
- 从而更不容易只记住训练集细节
L2 正则化(也叫 weight decay)是啥?
L2 正则化就是给损失加一项“惩罚大权重”:
这里的 是所有参数的平方和(你可以理解成“权重的能量”):
它的效果:让权重别长得太大,模型更平滑。
L1 正则化是什么?
L1 正则化用的是绝对值:
其中
效果:更倾向让很多参数变成 0(更“稀疏”)。
总结
- 正则化 = 在训练目标里加个“惩罚/约束”,让模型更稳、更能泛化
- L2 正则化(weight decay)= 惩罚权重平方和,让权重别太大
- L1 正则化 = 惩罚权重绝对值和,让权重更稀疏
Q6:Transformer
更新日志
afbd9-于3f935-于75be3-于3eeb0-于8e600-于a61bf-于5e992-于